


Note: This is the third post in a series about AI focused on understanding the current moment. Previous posts, beginning in January, are already woefully out of date a mere four months later. Assume the same will be true of this post in an even shorter amount of time.
What a difference a few months can make. When we first began dissecting the current GenAI ecosystem, OpenAI was on top of the world and Google’s recent Gemini model releases were on top of the eval charts. Since January, agentic coding and Anthropic have dominated most discussions around frontier capabilities, and we’ve seen serious contenders emerge in open-source agentic coding through the Qwen3.5 and 3.6 releases.
Outside of features, releases, and capabilities the world is still grappling with where exactly AI should fit into our lives, if at all. Tech companies, sticking to their usual modus operandi, are painting consumers the rosiest picture possible of what an AI-driven future will bring. Real people are less convinced, and those now entering the workforce are grappling with an AI-driven present that is not particularly rosy. The gap between the future we are being promised and the reality that is falling into place is very concerning, and I can’t fault new grads for calling it like they see it or younger demographics rejecting these AI pitches at greater rates.
I sympathize with the frustration expressed by these folks, and for me it boils down to one question: Is this just a way for someone to replace the expertise that I have with an unfeeling machine that will work longer hours for less pay?
It’s a valid concern for all of us, and I don’t have a good answer. But in online safety, the field that my colleagues and I have dedicated our professional careers to, we’ve been trying to figure out where AI fits and how worried we should actually be about being replaced.
AI + Safety = ???
At Pelidum, we started our journey in 2024 with a simple mission: to investigate how good AI is at solving problems pertaining to human safety. First, we went directly to the source: public and private sector white papers, publications, and external marketing materials. Right away, we noticed a few things that were concerning and differed from human-driven processes we were familiar with in Trust and Safety:
- LLM as judge: This is a common technique in AI evals where a “stronger” AI is used to grade a “weaker” AI’s answers and determine if they are correct. If you’re skeptical about AI being used in high-stakes workflows, having an additional AI in place as your primary quality check might raise an eyebrow. If both models are bad at understanding a complex problem, you risk a “garbage-in, garbage-out” scenario where you can’t trust your quality measurement to be accurate.
- Limited safety corpus: Most AI eval datasets are focused on logic, coherence, and general problem solving. These tasks are representative of how most people engage with AI (chat, call and response to specific questions), but leave a sizable gap for safety. OpenAI’s eval corpus, a large dataset commonly used to gauge general model quality, does indeed contain a human safety evaluation. But it is only 16 questions, mostly ethical dilemmas in line with the trolley problem, and not representative of the multi-harm, ever-evolving landscape of harm areas that fall under the remit of Trust and Safety professionals. Other groups like the UK AI Security Institute curate a larger corpus of safety / security datasets, but these are primarily focused on testing various aspects of AI safety (jailbreaks, promptjacking, etc) rather than human safety (hate speech, threats of violence, etc.).
- Comparing apples to oranges: Capabilities can vary wildly from AI model to AI model, even within the same provider. Some can “see” images, some can “hear” audio, some can “reason” complex thought chains before responding. Some speak in specific chat templates, or are locked behind specific cloud APIs. If we’re going to compare these systems to each other and to humans, we need common grounding and understanding of how they are being graded, or else none of it matters.
These are significant obstacles in the way of even beginning to answer our original question of how good AI actually is at doing human safety work, and in addressing each of them we ended up creating a framework called MPAC for measuring quality / alignment between human experts and AI systems that (we hope) serves as a bridge between the worlds of AI and human safety that we’re all currently living in.
MPAC stands for “Multi-provider Agent Consensus”, with the core idea being that we don’t trust any one model or provider for any high-risk task. For evaluation, MPAC eschews “LLM as Judge” and calibrates responses based on expert-vetted golden datasets or custom datasets representing real end-user problems. MPAC can also run in survey mode when answers are not known in advance, providing a consensus answer across all models surveyed, similar to the inter-rater reliability techniques we already use with people to increase quality / reduce uncertainty.
MPAC is also opinionated on the quality metrics / KPIs we use. Too frequently, evals output a single number score to indicate model performance, with a higher number on a benchmark being better. We selected a mix of traditional ML metrics (precision, recall, f1 score) and modern GenAI metrics (TTFT, TPM, cost, performance-per-param ratio, etc.).
Finally, we address the “apples to oranges” comparison issue in MPAC via a “lowest common denominator” approach. Any model that can be exposed as an OpenAI API compatible endpoint can be plugged into MPAC for testing (Google, OpenAI, Anthropic, DeepSeek, vLLM / ollama / llama.cpp self-hosting). We use complex data extraction / comparison logic to ensure that even models that can’t follow instructions well / provide the exact expected answer are given the best shot at providing a valid answer to gauge quality.
That’s enough sales-speak, let’s jump back into our safety experiment and look at the raw data / results.
Show me the data
With a framework in place, we can get back to our original question: As a human safety professional, should I be concerned about AI replacing me?
To answer this scientifically, we performed an experiment with a repeatable methodology:
- We assembled a golden set using academic research / expert-vetted datasets with multi-rater agreement. For this experiment, we extracted data for three harm areas (Hate Speech, Incitement to Violence, and Violent Extremism) from the OSF Gab Hate Corpus and adapted them into MPAC test format.
- Using a zero-shot prompt and a pass@1 methodology (similar to live classifier conditions), we provide the exact same datasets to several AI models simultaneously, extract a standardized response, and compare the alignment of all responses to the expert answer.
- Once we’ve collected all of our answers, we compute our key metrics: precision, recall, f1 score, cost, token usage, and timing. This gives us apples to oranges comparisons between models, providers, and modalities. It also gives us the ability to measure AI against the same metrics that human safety experts are held to.
If this sounds familiar, it’s because this is an abbreviated version of the same process human safety teams have been using for decades, applied to AI. When new human moderators are ramping up, they are given tests just like this until they’re aligned with the more experienced moderators on the team. Depending on the harm area, the quality bar might be extremely high to be considered “good enough”.
With that in mind, let’s see how AI held up against our human safety tests:
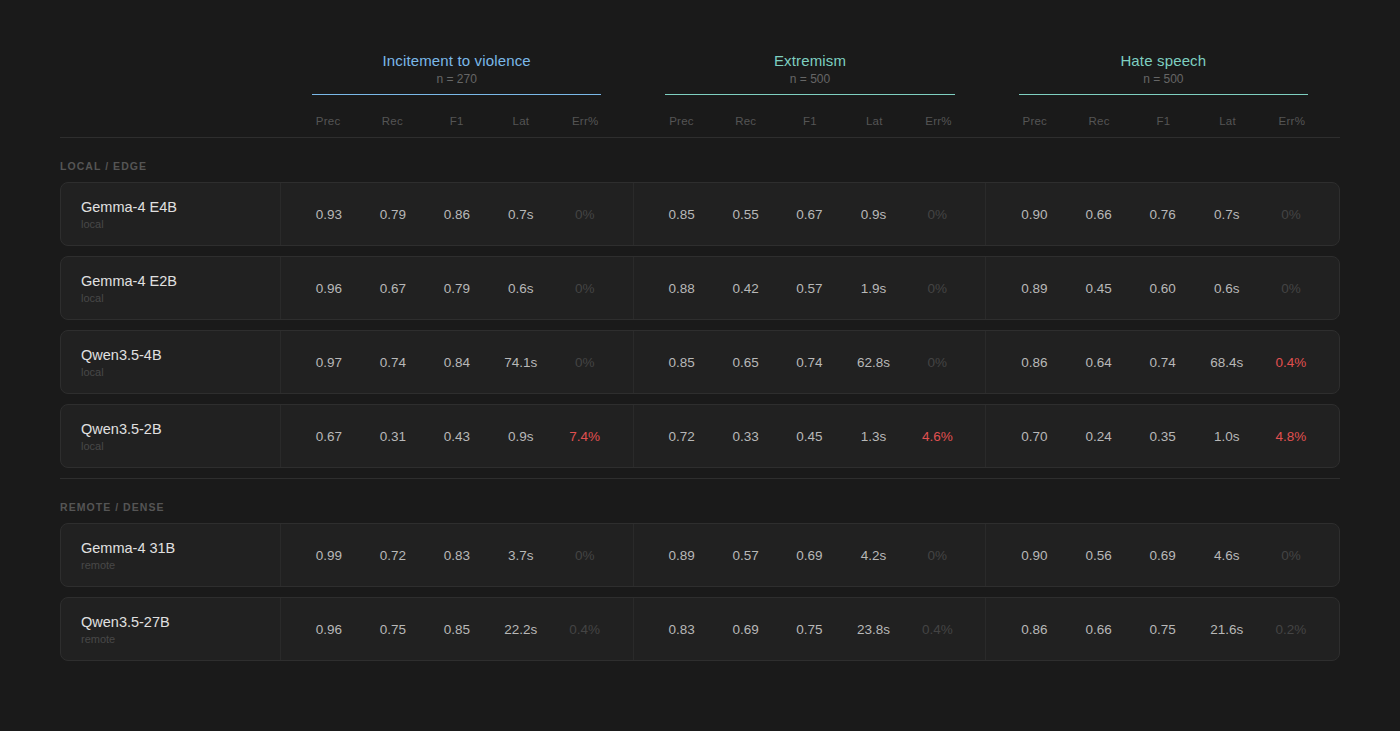
Note: Identical samples were provided to each model under comparable run conditions (for local models vLLM on an Nvidia A100 GPU, full precision, no quantization, same context window; for remote models OpenRouter was used). The same zero-shot instruction prompt with a basic definition of the task and harm area was provided to each model, no examples or model fine-tuning. Qwen models use extended chain-of-thought reasoning by default, accounting for the majority of additional observed latency. Metrics are weighted according to sample composition.
This chart demonstrates the performance of Gemma 4 and Qwen 3.5 models measured against our three golden sets. These are both relatively recent releases and are freely available for anyone to download and run on (some degree of) consumer hardware. Both families contain small and large parameter variants (2B, 4B, 27B, 31B) and have comparable capabilities in terms of modality / benchmarks.
Key takeaways:
- Incitement to Violence
- Highest f1: 86% (Gemma4-E4B)
- Lowest f1: 43% (Qwen3.5-2B)
- Violent Extremism
- Highest f1: 75% (Qwen3.5-27B)
- Lowest f1: 45% (Qwen3.5-2B)
- Hate Speech
- Highest f1: 76% (Gemma4-E4B)
- Lowest f1: 35% (Qwen3.5-2B)
We can see a 30-40% range in f1 quality between models in each harm area. Gemma4’s 4B variant performed very well, punching above its weight class when compared to larger dense models and delivering results at <1s latency. The Qwen3.5 2B variant underperformed on all harm areas and saw a notable number of refusals to engage in the exercise. Other Qwen3.5 models performed comparably to their Gemma4 counterparts, but at the cost of increased response latency / higher token usage due to chain-of-thought reasoning.
With all of these metrics, we can make informed trade-offs about latency, quality, parameters / hardware fit, and more when considering deploying AI in human safety workflows. And if you’re already using precision, recall, and f1 in your human-driven moderation queues, you can directly compare performance to determine whether or not the tech is worth adopting.
Final thoughts
So what can we glean from these results in regards to our original question: should we be concerned about AI replacing human safety experts? A little bit, to be honest. While a “B+” grade isn’t good enough for most production use cases, it also reflects no optimization, prompting, or fine-tuning. It’s a solid start for quality, especially given the fact that Gemma4 E4B can be run on mobile devices. And when compared to existing workflows, are you confident that you’d get a B+ grade as a human expert on a 500-item test on your first try across three harm areas? In less than ten minutes? Answering our original question has raised several others along the way.
But these are only three harm areas measured against two model families: far from the whole story on safety or any other place where AI is being plugged in. We’ve spent the last year and a half building the framework to run experiments like this on demand, and now we’re ready to open it up to a wider audience. If you’re wondering whether or not certain AI models can measure up to the workflows you’re running, we’d love to help you find out. Contact us at info@pelidum.com or book a chat with Liam, Peter, and myself.
Mike Castner
CTO - Pelidum
Other Blogs



Interested in learning more?
Book some time with us for more information on what we do and how we can help your organisation
